Execution workflow
When the user gives command to execute a processing task, the following happens:
- Server verifies that execution is not already in process.
- To simplify matters we allow only one execution per task definition. This is only a slight practical limitation as nothing prevents the user from copying the exact task definition under another name (via export/import round-trip).
- The current configuration is retrieved.
- A snapshot of the the parsed input specified in the configuration is made.
- This prevents possible corruption of the result display in case the formatting of the original file changes between the start of processing and the result presentation. This might cause columns mismatch and other undesirable effects.
- The parser also automatically detects line separators and remembers them to apply in outputs.
- This prevents possible corruption of the result display in case the formatting of the original file changes between the start of processing and the result presentation. This might cause columns mismatch and other undesirable effects.
- A Runnable instance is created, which does the following:
- The parsed input is converted to the working table format of the core algorithm.
- Interpreters associated with the defined knowledge base proxies are provided with the table and started one by one (although parallel computation is about to be explored in future releases), each applying the algorithm on the table, constrained by the optionally provided user feedback from previous runs.
- Their results are merged into single result which is cached and set as a Future result, waiting for retrieval by the client or returning immediately if the retrieval call has already been made.
- The Runnable instance is submitted to ExecutorService and the returned Future is associated with the user's ID and task ID, but not before the previously cached result is purged.
When the command to cancel the task is received, it is passed on the Future. Unfortunately in the current version it is not possible to actually stop the execution and it always has to go through even if it does appear stopped the client code. At least until cooperative handling of thread interruption is introduced to the algorithm code. The problem lies in the Solr caches, which do not handle the pre-emptive interruptions well and are in the risk of corruption if the client code does them.
Execution states
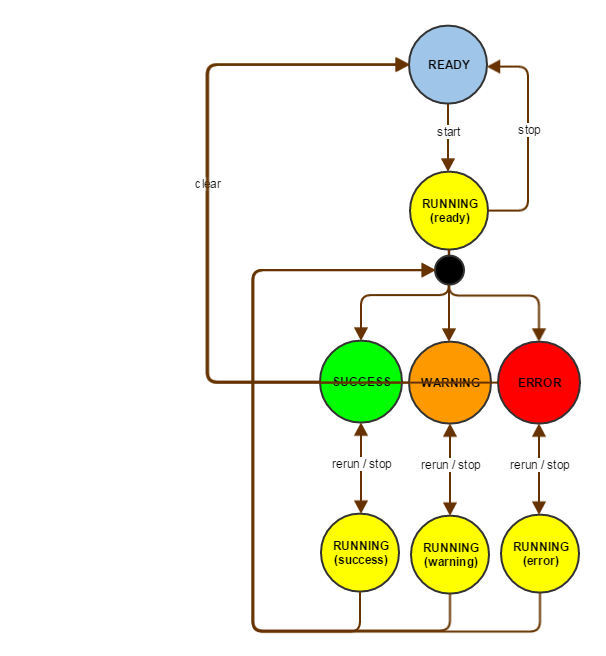
The state of the Future (whether it it is done, and if so, if it is cancelled) and whether there is even any associated with the task, or a result is cached, determines the possible execution states of the task. It is the caching in persistent storage, that slightly complicates things against the memory-only version, because the Futures naturally cannot be serialized, and any exceptions raised during the task processing even less so. This causes the ERROR state to be lost upon server restart, which was ultimately deemed an acceptable result, compared with the effort needed to keep the arbitrary error cause serialized. Naturally the task result is available only when the execution is in the SUCCESS or WARNING state.
The warnings presented when querying the result from the WARNING state are collected from minor runtime exceptions that occur throughout the algorithm execution. The motivation for their introduction was the fact that in the original algorithm version even minor setbacks, like temporary HTTP connection problems, caused the entire processing to halt, which was frustrating in cases when the processing took several-hours to repeat.
Task processing result
Odalic internal model of table annotations (cz.cuni.mff.xrg.odalic.tasks.results.Result), presented on the outside by the REST API, is geared towards making the working of the client easier first, rather than truly reflect any theoretical model. It has the following parts:
- subjectColumnPositions
- mapping of knowledge bases to subject columns
- subject columns (concept similar to a primary key, all the relations lead from them) are determined through the run of the algorithm for each base in its own interpreter
- mapping of knowledge bases to subject columns
- headerAnnotations
- each column gets assigned an RDF class per knowledge base and that implies that all the cells in the column are its instances
- Actually there are usually multiples candidates, which are ordered according to their score and left for the user to choose from, if not satisfied with the default choice.
- each column gets assigned an RDF class per knowledge base and that implies that all the cells in the column are its instances
- cellAnnotations
- A matrix of RDF resources, one per each cell at most, that disambiguate the original cell content.
- The format of the cell annotations is actually quite similar to those in headers, as there is not much need to distinguish between them for most uses.
- A matrix of RDF resources, one per each cell at most, that disambiguate the original cell content.
- columnRelationAnnotations
- RDF properties forming a relation between two columns.
- The domain of the property conforms to the class of the first column, the range to the second one.
- RDF properties forming a relation between two columns.
- statisticalAnnotations
- They assign set of property to each column per base and a type indicating whether the column is a measure of dimension of the formed data cube.
- Applies only when a statistical processing was chosen during the task configuration. This basically means that no relations were formed, and the choice of subject column was also dropped, because what matters is the final data cube formed during the export.
- columnProcessingAnnotations
- Explicit information whether the column was declared by the algorithm to contain named entities (most of the disambiguated content), non-named entities (typically numerical values) or if the column was ignored by the algorithm (on the user's request) during the process.
- warnings
- List of warnings in the order as they were written when non-fatal errors occurred during the processing.
These parts are adapted from the filled by adapting the result representation provided by the algorithm (uk.ac.shef.dcs.sti.core.model.TAnnotation), which by itself is not suitable to be passed around, but designed to be modified during the processing.
Annotation structure
Every annotation (for headers, cells, relations,...) has the following structure:
- Map from knowledge bases to ordered set of candidates.
- Every candidate is composed from the actual resources description and score assigned by the algorithm.
- Resource description has a label and the resource URI (optionally prefixed as is common in many common representations).
- Every candidate is composed from the actual resources description and score assigned by the algorithm.
- Map from knowledge bases to the set of chosen candidates.
{kind=link}
{kind=link}