Page for creation of a new task configuration can be opened from the main menu - item Tasks > Add new or from the List of tasks - button Add new at the bottom of the page.
Basic settings
Basic task settings include Task identifier and description. Task identifier must not be empty and may contain only alphanumeric characters, spaces, dots, commas, underscores and dashes. After creation the task identifier cannot be changed, but you can always re-import the task under different identifier.
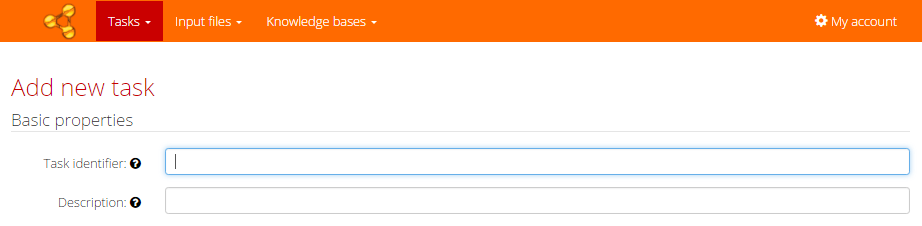
Setting the input file
You can select one of the already defined files, than skip to the File format configuration. Or you can add a new file. There are two options to do that:
Local files
You can upload a file from your device. The identifier will be filled automatically with the file name, but you can change it (restrictions are the same as for the task identifier).

Remote files
Or you can attach a remote file. Just fill the location of the remote file and custom identifier.
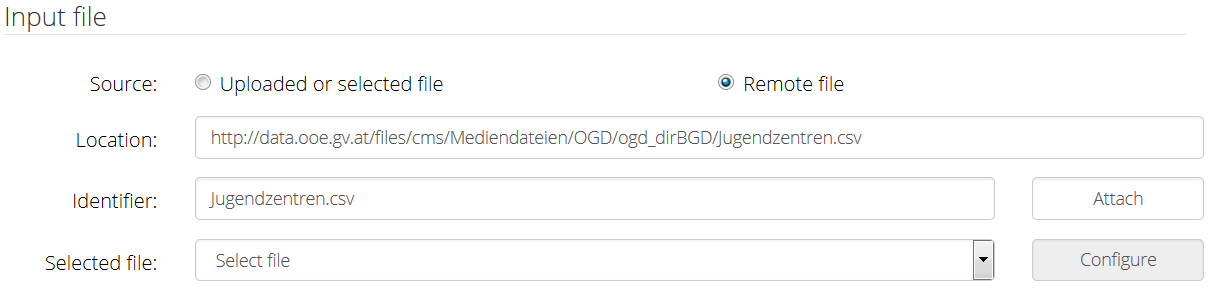
File format configuration
Select some file for processing in the task from the list of uploaded or attached files labelled Selected file. You can optionally configure format settings of the selected file (the dialog is opened in modal window):
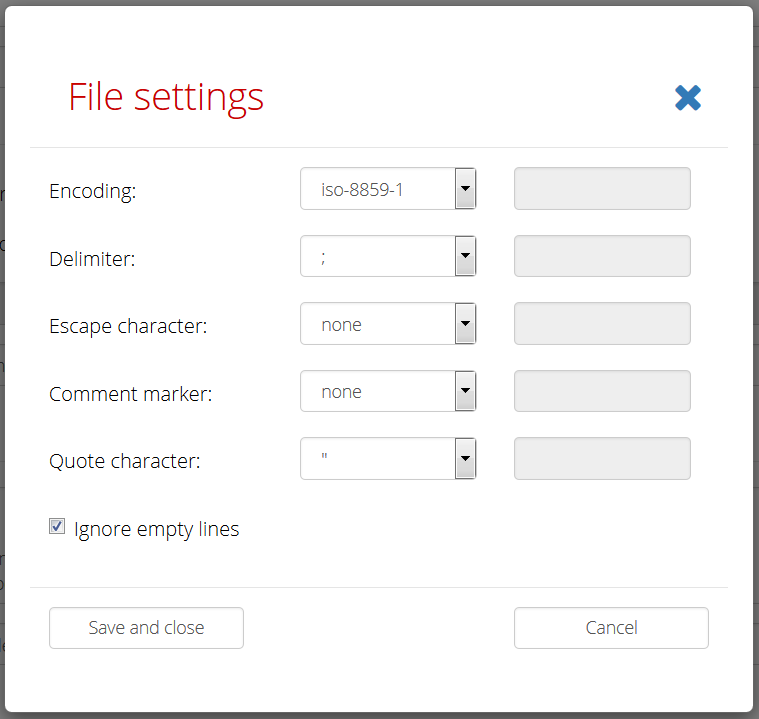
You can select some of predefined values or you can fill custom values. Custom character set names must be on of those provided in https://docs.oracle.com/javase/8/docs/technotes/guides/intl/encoding.doc.html. Delimiter separates records in one row. Quote character marks start and end of section where delimiters are ignored. Escape character escapes the quote character. Comment marker turns on comments until the end of line. You can also tell the application to Ignore empty lines.
Knowledge bases
Select knowledge bases which will be used in the task processing. Available knowledge bases and their properties are set by configuration files. Their structure is described at Configuration part of the developer documentation. To turn them on they must be linked to from the main configuration file.

Select also the primary knowledge base, which is modifiable, so it will be used for proposing new entities. During export of results, the concepts from the primary knowledge base are preferred.
Processing
In the last section you can restrict the number of lines processed in the task (including the header). Also check whether you want to process the file as statistical data - in this case the relation discovery phase will be skipped, but statistical annotations will be assigned instead. They are then used when exporting results according to the RDF data cube standard.

You can save the task, save and immediately run, or cancel the changes.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}