This file represents annotations to the extended CSV file according to the CSV on the Web standard. It contains metadata for each of "physical" columns of the CSV file and also for extra "virtual" columns describing classifications, relations or statistical data cube.
Model of Annotated table
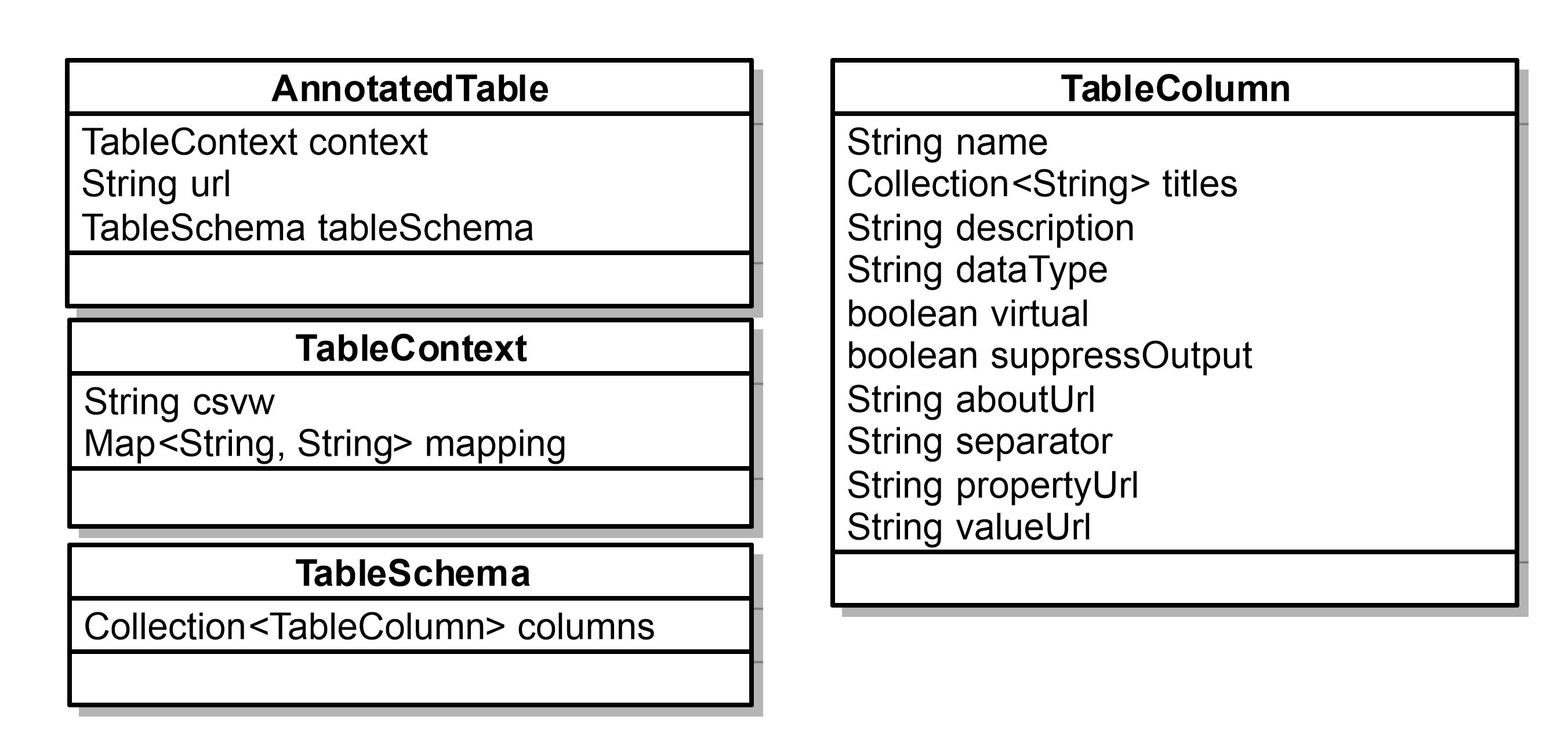
Example
{
"@context": "http://www.w3.org/ns/csvw",
"url": "file.csv",
"tableSchema": { "columns": [
{ "name": "City", "titles": [ "City", "LAU_NAME, "Town" ], "dc:description": "City of Austria", "datatype": "string"
"aboutUrl": "{City_url}",
"propertyUrl": "dcterms:title"},
{ "name": "District", "titles": [ "City", "DISTRICT_NAME" ], "dc:description": "District of Austria", "datatype": "string"
"aboutUrl": "{District_url}",
"propertyUrl": "dcterms:title"},
{ "name": "POP_FOR_NAT", "titles": [ "Population of foreigners" ], "dc:description": "Population of foreigners in the given area", "datatype": "string"
"aboutUrl": "{City_url}",
"propertyUrl": "x:hasPopulationNat"},
{ "name": "POP_TOTAL", "titles": [ "Population Total" ], "dc:description": "Total Population in the given area", "datatype": "string"
"aboutUrl": "{City_url}",
"propertyUrl": "x:hasPopulationTotal"},
{ "name": "City_type",
"virtual": true,
"aboutUrl": "{City_url}", //relies on value within the column City - does it take valueUrl automatically (if available)?
"propertyUrl": "rdf:type",
"valueUrl": "http://adequate.at/concept/city"},
{ "name": "City_url", //do not produce to the output JSON, this is used only to hold identifier for the row/part of the row
"suppressOutput" : "true",
"datatype": "anyURI"
"valueUrl": "{City_url}"
{ "name": "City_alternative_urls", //in the form "http://example.org/1 http://example.org/2"
"aboutUrl": "{City_url}", //relies on value within the column City - does it take valueUrl automatically (if available)?
"separator": " ",
"propertyUrl": "owl:sameAs",
"valueUrl": "{City_alternative_urls}"},
{ "name": "District_type",
"virtual": true,
"aboutUrl": "{District_url}",
"propertyUrl": "rdf:type",
"valueUrl": "http://adequate.at/concept/district"},},
{ "name": "District_url",
"suppressOutput" : "true",
"datatype": "anyURI"
"valueUrl": "{District_url}, },
{ "name": "City_District_liesIn",
"virtual": true,
"aboutUrl": "{City_url}",
"propertyUrl": "ad:liesIn",
"valueUrl": "{District_url}"}, },
}, //end of table schema
} //end
Export process
First the annotations for original columns are created. They include original column name (also as title), dataType String and when the column is disambiguated, then the relation between corresponding *_url column and the column name with predicate dcterms:title is added. When the disambiguations exist, the annotations for *_url (which only holds the URI of disambiguation), resp. *_alternative_urls (which describes also relation between *_url and *_alternative_urls with predicate owl:sameAs) are also created.
Then the header annotations (classifications) from the Result are read and for each of them the virtual column describing the relation between *_url and classification resource with predicate rdf:type is created.
Finally the column relation annotations from the Result are read and corresponding virtual columns are created. The subject must be always resource. But the object can be also literal (for example string or number). In this case we must also find the object dataType, which is derived from the Range property of the relation predicate entity.
Statistical data specifics
When statistical data are processed, some more columns (apart from columns with original input values, columns with disambiguation and alternative disambiguation URLs and virtual columns describing classifications) are added to the Annotated table JSON (virtual columns describing relations are not present, because relation discovery part of the algorithm is skipped). Some newly added virtual columns describe just one certain triple (without links to columns), because it is needed for definition of data cube.
When the URL is written in prefixed form (compact IRI), the appropriate prefix mapping is added to the "@context" attribute of annotated table. The "@context" attribute then contains array with two objects: first item is String with link to the definition of CSV on the Web standard context, second item is a map with prefixes used in the document (local context).
Dataset definition includes three virtual column with concrete triples: {datasetUri} rdf:type qb:DataSet , {datasetUri} dcterms:title {inputIdentifier} and {datasetUri} qb:structure {dsdUri} , where datasetUri is generated accoridng to the template "{kbInsertSchemaElementPrefix}dataset/{UUID}" and dsdUri according to "{kbInsertSchemaElementPrefix}dsd/{UUID}" , inputIdentifier is set by user during file upload and kbInsertSchemaElementPrefix is fetched from the KnowledgeBase configuration (property called kb.insert.prefix.schema.element).
Data structure definition includes one virtual column with triple: {dsdUri} rdf:type qb:DataStructureDefinition.
Then we add column "OBSERVATION_url" as holder for URLs of observations (similar as other "*_url" columns for URLs of disambiguations) and two virtual columns linking the "OBSERVATION_url" with rdf:type predicate to qb:Observation and with qb:dataset predicate to {datasetUri}.
Component definition includes two virtual columns with concrete triples: {dsdUri} qb:component {compUri} and {compUri} {kind} {colPredicate} , where compUri is generated according to template "{kbInsertSchemaElementPrefix}dimension/{UUID}" in case of dimension component or "{kbInsertSchemaElementPrefix}measure/{UUID}" in case of measure component, kind is qb:dimension for dimension or qb:measure for measure and colPredicate is set by user in feedback (predicate describing concrete relation of dimension or measure associated with column of input file).
Next part is slightly different for dimension and for measure. Dimension definition includes triples: {colPredicate} rdf:type rdf:Property , {colPredicate} rdf:type qb:DimensionProperty , {colPredicate} rdfs:label {colPredicateLabel} and {colPredicate} qb:concept {colClassification} , where colPredicateLabel is label associated with colPredicate entity and colClassification is entity used for classification of the column. Measure definition includes triples: {colPredicate} rdf:type rdf:Property , {colPredicate} rdf:type qb:MeasureProperty , {colPredicate} rdfs:label {colPredicateLabel}, {colPredicate} qb:concept {colClassification} and {colPredicate} rdfs:subPropertyOf sdmx-measure:obsValue .
And finally there is a virtual column describing relation between OBSERVATION_url column and the column which is associated with the component. Relation predicate is colPredicate. In case of dimension component the link points to the *_url column with disambiguation URLs. For measure component the link points to the original column, which is not disambiguated, because it does not contain named entity.